This blog post has a Google Colab where you can follow along, if you prefer to jump into the code straight away.
What's a Matcher?
Spacy has a beautifully designed, flexible Matcher class, which allows matching for arbitrary tokens/token sequences based off of a lot of different attributes. The Matcher is very powerful, and allows you to bootstrap a lot of NLP based tasks, such as entity extraction.
However, sometimes you want to look for patterns that occur at the sentence level, or involve multiple words/phrases in a structured format. This particularly occurs with relation extraction, where you might know that a lot of different patterns correspond to the same relation, but don't always occur next to each other in sentences. For example,
- X was founded by Y
- X, a company which has raised $3 trillion in revenue, was founded by Y
Both express the same relation, but the second is hard to capture with the Matcher, because the intermediate clause could contain a variable number of words, which means we can't use the wildcard token match functionality in the word level Matcher.
You can imagine lots of "relation extraction adjacent" tasks which would benefit from being able to do this type of "structural" matching - mainly tasks where you need a small amount of structure in your output (for example, parsing the quantity, frequency and dose of a drug prescription, or the price and timing of a buy call in finance).
If you only need to match a fixed number of wildcard tokens, you should just use the Matcher syntax for this, which is to just pass an empty dictionary for a token.
The DependencyMatcher
SpaCy has a lesser known DependencyMatcher, which allows you to match on dependency paths using semregex syntax.
Semregex is basically a way to describe a subtree pattern that you want to search for within a full dependency tree. We describe nodes with normal token attributes, but also how these nodes should connect to other nodes in the tree. Specifying the syntax for this directly is difficult (both in semregex and in spacy's version of it), so we'll look at some functions below which can help.
The SpaCy Semregex Format
The SpaCy semregex format is similar to the patterns you pass to the Matcher, with a few extras to account for the fact that we can specify how the nodes connect to each other. For a single node we want to match on, it looks like this:
{
"PATTERN": {...},
"SPEC": {...}
}And a full DependencyMatcher pattern is just a list of these dictionaries.
The PATTERN field
We'll start off with the simplest field. The "PATTERN" field is identical to the pattern you might pass to the normal word level spacy Matcher, specifying word level attributes for this node. So for example,
{
"POS": "NOUN",
"LEMMA": "dog"
}would match any word which is a noun and also has the lemma 'dog'. So far, so similar to the Matcher. The fields that are available to match on are exactly those available for the word matcher.
The SPEC field
The SPEC field will specify how the nodes within the subtree that we are trying to match relate to each other.
{
"NODE_NAME": "str",
"NBOR_RELOP": "str",
"NBOR_NAME": "str"
}- NODE_NAME: The unique name for this node.
- NBOR_RELOP: A Semregex operator specifying a relation between two nodes (e.g parent:child, or child:parent). To make things simpler, there is a way to construct the dependency matcher patterns such that this field is always set to the value ">".
- NBOR_NAME: The name of the node which we are specifying that this node must be connected to.
Overall, there are two complicated things about using the DependencyMatcher.
-
The NBOR_RELOP field only allows you to express structural relations between nodes (such as parent, child, govenor, preceeds) and not based on dependency types. Instead, we express the structural relation through the spec, and the dependency label through the PATTERN field, as spacy tokens have a
Token.dep_attribute, which specifies the dependency label for the arc connecting the token to its parent. -
When you pass your pattern into the dependency matcher, it walks over your patterns, constructing it's representation. When it does this, it assumes that the rules are ordered in a way such that when you reference a node in the
NBOR_NAMEfield, it has already been seen by the matcher in the list of rules. In the next section, we'll introduce a way to overcome this by making a simplifying assumption about what we want to match against.
A Simplifying Assumption
When thinking about matching on subtrees, it makes everything easier if we make the following simplifying assumption:
**We will only create matching rules for nodes of the form Parent > Child **
This helps resolve both of the complicated things we noticed above:
-
Specifying the dependency relation which connects two nodes now corresponds to setting the
{"DEP": "relation_type"}in the pattern dictionary of the child token. -
Now that we know that we will only be referencing a node's parent, if we add the rules we create in a Depth First Search ordering, our subtrees are guaranteed to be accepted by the
DependencyMatcher, because a node's parent will always exist before a child tries to reference it.
Now we've got our head around the formatting, we can start looking at some code which will help us to generate the patterns, as well as verify them.
def construct_pattern(dependency_triples: List[List[str]]):
"""
Idea: add patterns to a matcher designed to find a subtree in a
spacy dependency tree. Rules are strictly of the form
"Parent --rel--> Child". To build this up, we add rules
in DFS order, so that the parent nodes have already been added
to the dict for each child we encounter.
# Parameters
dependency_triples: List[List[str]]
A list of [parent, relation, child] triples, which together
form a tree that we would like to match on.
# Returns
pattern:
A json structure defining the match for the given tree, which
can be passed to the spacy DependencyMatcher.
"""
# Step 1: Build up a dictionary mapping parents to their children
# in the dependency subtree. Whilst we do this, we check that there is
# a single node which has only outgoing edges.
root, parent_to_children = check_for_non_trees(dependency_triples)
if root is None:
return None
def add_node(parent: str, pattern: List):
for (rel, child) in parent_to_children[parent]:
# First, we add the specification that we are looking for
# an edge which connects the child to the parent.
node = {
"SPEC": {
"NODE_NAME": child,
"NBOR_RELOP": ">",
"NBOR_NAME": parent
}
}
# We want to match the relation exactly.
token_pattern = {"DEP": rel}
# Because we're working specifically with relation extraction
# in mind, we'll use START_ENTITY and END_ENTITY as dummy
# placeholders in our list of triples to indicate that we want
# to match a word which is contained within an entity (or the
# entity itself if you have added the merge_entities pipe
# to your pipeline before running the matcher).
if child not in {"START_ENTITY", "END_ENTITY"}:
token_pattern["ORTH"] = child
else:
token_pattern["ENT_TYPE"] = {"NOT_IN": [""]}
node["PATTERN"] = token_pattern
pattern.append(node)
add_node(child, pattern)
pattern = [{"SPEC": {"NODE_NAME": root}, "PATTERN": {"ORTH": root}}]
add_node(root, pattern)
return patternThe DependencyMatcher will return something that looks like this:
[(13439661873955722336, [[6, 0, 7]])]What we are looking at here is a list of Tuples pairing the ID of
the matching pattern to a list of all the subtrees of the doc which match it.
In the case above, there is only one pattern, but it's quite common for simple subtrees
that you might search for to occur multiple times in a single sentence.
Usage
from spacy.matcher import DependencyMatcher
from spacy.pipeline import merge_entities
nlp = spacy.load("en_core_web_sm")
nlp.add_pipe(merge_entities)
example = [
["founded", "nsubj", "START_ENTITY"],
["founded", "dobj", "END_ENTITY"]
]
pattern = construct_pattern(example)
matcher = DependencyMatcher(nlp.vocab)
matcher.add("pattern1", None, pattern)
doc1 = nlp("Bill Gates founded Microsoft.")
doc2 = nlp("Bill Gates, the Seattle Seahawks owner, founded Microsoft.")
match = matcher(doc1)[0]
subtree = match[1][0]
visualise_subtrees(doc1, subtree)
match = matcher(doc2)[0]
subtree = match[1][0]
visualise_subtrees(doc2, subtree)
Running the above code results in the following subtrees:
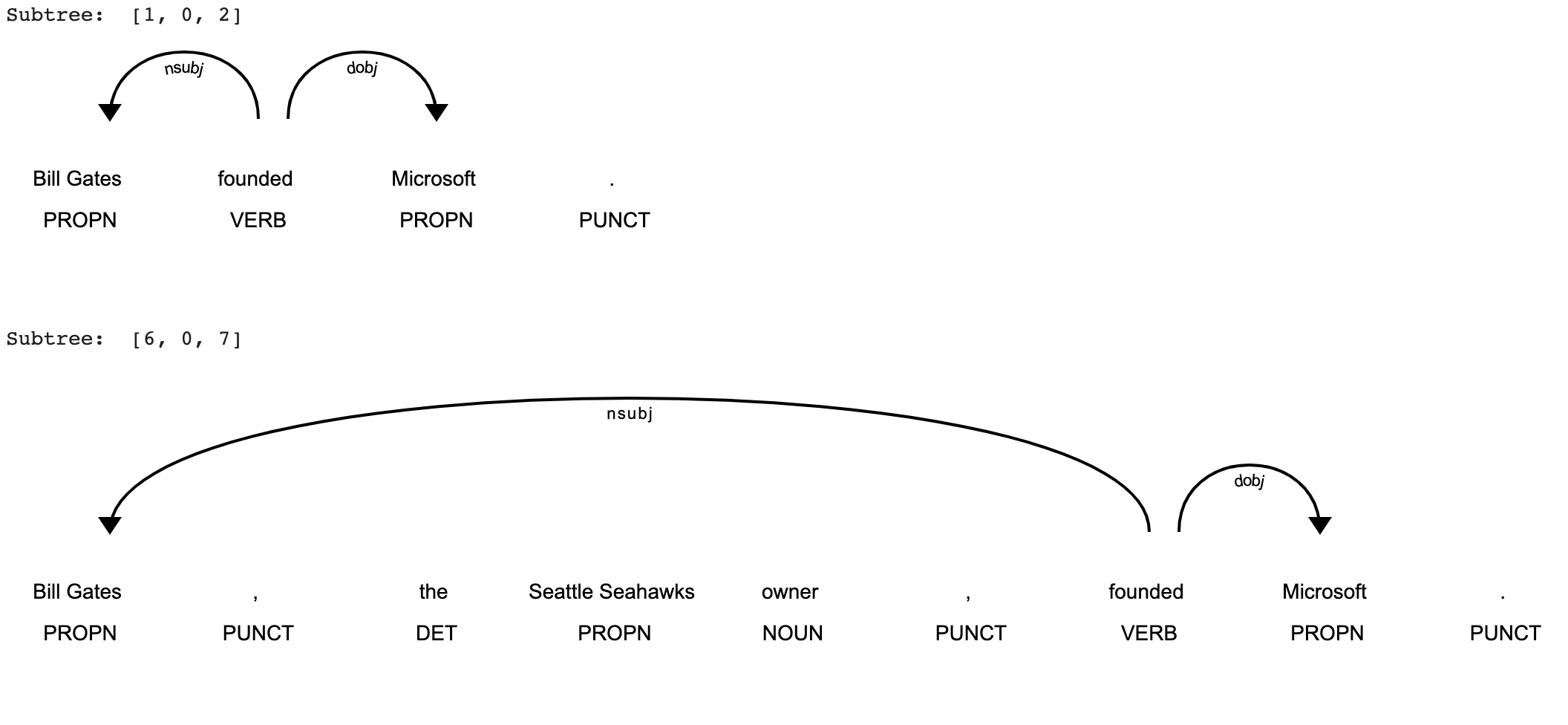
So we've successfully matched a dependency path which often expresses a relation!
This blog post is just an example, but you can imagine mining a larger amount of
dependency paths from raw text which connect entities (perhaps bootstrapped using the Matcher)
and using Prodigy to refine a dataset of relation extraction examples.
!!! Warning When searching for subtrees, bear in mind that it is easy to quite quickly make a search very computationally expensive, in particular when you add nodes which are under specified (e.g there are no constraints on what the node must look like). For example, with 2 completely undefined nodes connecting 2 nodes defined by entities, we may have to check all possible paths of length 4 between all possible pairs of entities.
There are probably ways to improve the performance of edge cases like this (such as pruning the tree that you search upfront to contain only nodes that are plausible), but given that this is a reasonably experimental feature anyway, it's fair enough to assume that the trees that you search for aren't too generic. Bear that in mind!
Conclusion
Overall, the DependencyMatcher can be a useful tool in your SpaCy toolbox for doing more complicated,
linguistically motivated data mining, particularly for tasks such as relation extraction. Hopefully,
with some of the code snippets above, you'll be able to work around the complexity involved in using it,
and create some cool applications.
All the code for this blog post (and some more, for visualisation) is available in this Google Colab.
There are lots of possible extensions to this blog post - for example, i've been working on a relation extraction system using the public data available from "A global network of biomedical relationships derived from text". This paper applies Ensemble Biclustering for Classification to dependency paths between entities, hierarchically clustering them in an unsupervised way into different groups of interaction relations for several different entity types. The paper is very good, I would recommend it!
There's a more complicated colab here with some work in progress analysis of the dependency paths they have provided for one of the entity types they provide in their data release. I'm working on distilling the paths they provide into a smaller set of higher precision patterns, which could be used more effectively for relation extraction. I'm not sure how it will turn out!